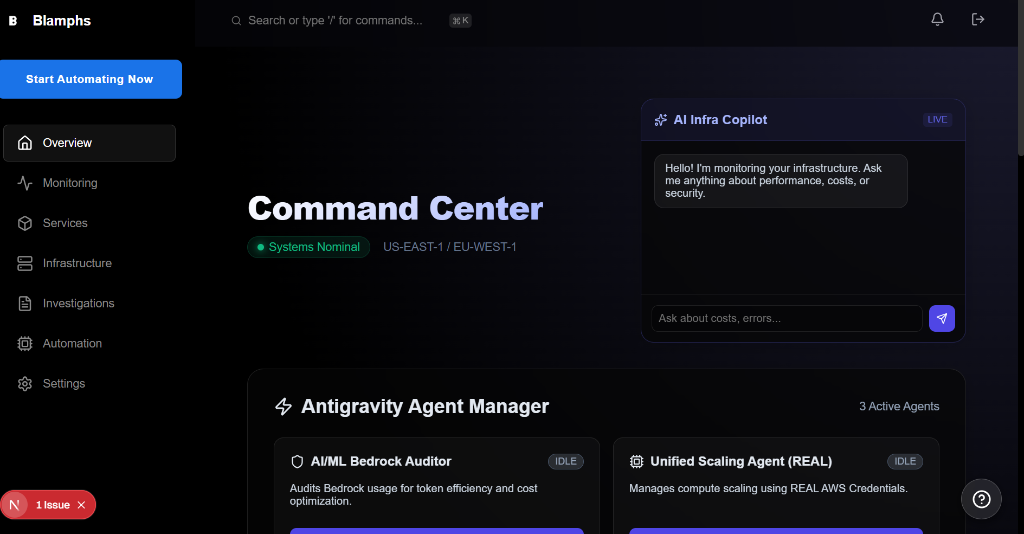
AI System Status: Optimizing Clusters...
Automate AI Infrastructure
in Minutes, Not Months.
Built for the AI Age.
Autonomous Optimization
Our agent constantly analyzes your cluster's utilization. It spots idle GPUs, proactively scales down to save money, and scales up millseconds before you hit capacity.
Self-Healing
Detects CUDA errors and zombie processes. Automatically cordons and reboots nodes.
Instant Forecasts
Predictive budget modeling based on your historical training runs.
Stop Wasting Money in the Cloud.
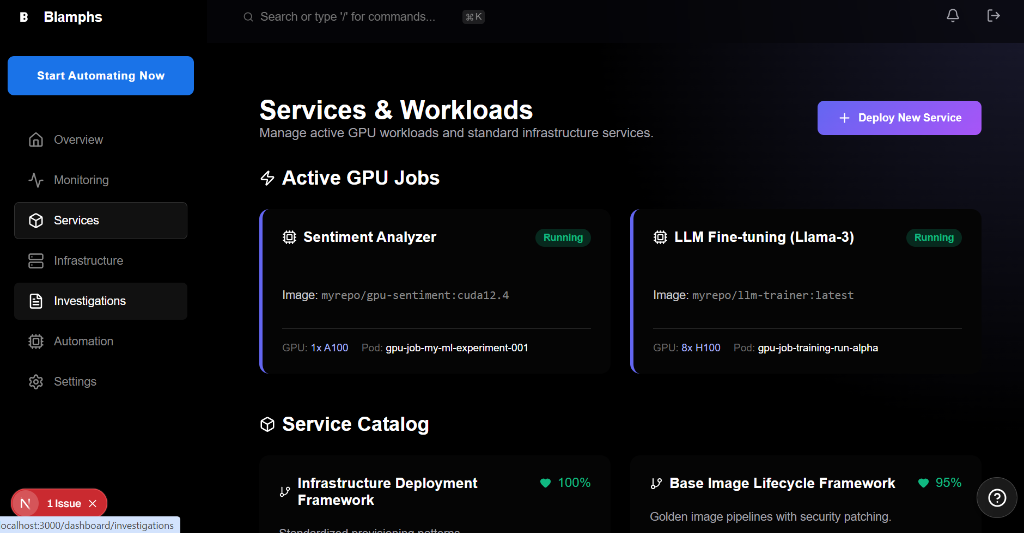
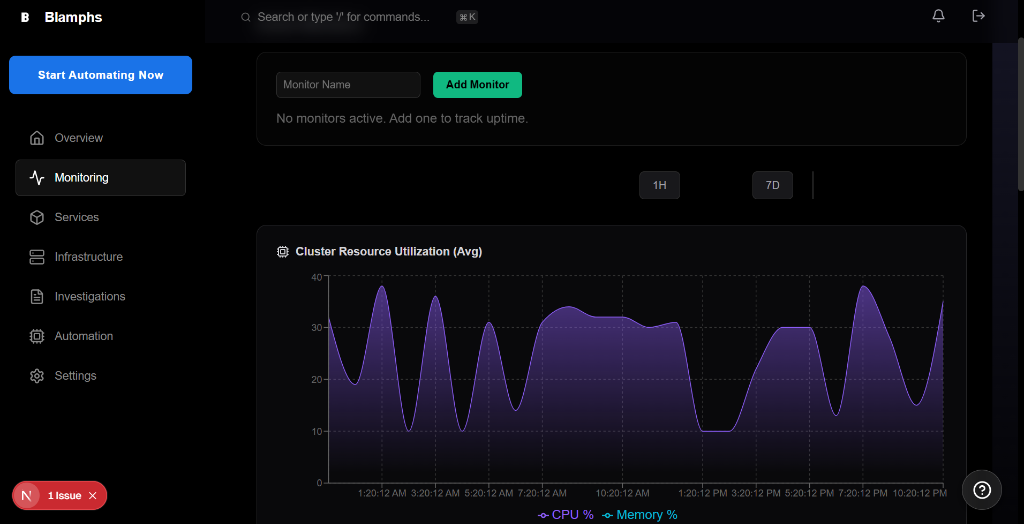
> blamphs connect --aws
Authenticating with IAM...
✓ Connected to AWS us-east-1
Scanning for EC2 instances...
Found 24 g5.2xlarge nodes.
01. Connect
Securely link your cloud provider with a single read-only IAM role. We map your entire infrastructure in seconds.
02. Configure
Define your constraints. Set budget caps, preferred instance types, and scaling boundaries using simple natural language.
03. Scale
Sit back. Our engine monitors your specialized hardware 24/7, handling interrupts and scaling instantly so you never pay for idle time.